从构建 Claude Code 学到的:Prompt Cache就是一切
工程圈有句老话——"缓存主宰一切"。做Claude Code这样的智能体产品也如此。
像 Claude Code 这种需要长期运行的智能体产品,能跑起来的关键就是Prompt Cache。它让我们能复用之前的计算结果,把延迟和成本都打下来。
那Prompt Cache到底是什么?怎么工作的?技术上怎么实现?这些可以看Prompt auto-caching with Claude这篇文章,讲得很清楚。
许多 AI 应用在多轮对话中会重复使用相同的上下文。例如,智能体通常以循环方式执行操作,每次操作都会产生新的上下文。由于 LLM 的 API 是无状态的,它不会记住过去的行为,因此智能体必须在每一轮对话中,将新产生的上下文与之前的行为、工具描述和通用指令一起打包处理。
这意味着,在多轮对话中,大部分上下文内容是重复的。如果没有缓存,每轮对话都需要为整个上下文窗口付费。为了尽可能复用这些共享的上下文内容,Prompt Cache应运而生。

在 Claude Code,我们整个架构就是围着Prompt Cache转的。缓存命中率高,成本就低,我们就能给订阅用户更宽松的额度。因此缓存命中率是我们关注的核心指标之一。
下面是我们优化Prompt Cache踩过的坑,很多都挺反直觉的。
一、设计有利于缓存的提示词布局
Prompt Cache的核心机制是前缀匹配。API 会从请求开头一直缓存到每个 cache_control 断点。所以顺序很重要——你要让尽可能多的请求共享相同的前缀。
最理想的结构是:静态内容在前,动态内容在后。Claude Code 的排序是这样的:

静态系统提示词 + 工具定义(全局缓存)
Claude.MD 文件(项目级缓存)
会话上下文(会话级缓存)
对话消息
这样不同会话之间就能最大化共享缓存。
但这个顺序其实很脆弱。我们踩过的坑包括:
在静态系统提示词里放了详细的时间戳(时间戳无时无刻不在变动,会导致缓存整体失效)
工具定义的排序不稳定
更新了工具信息
任何一点变动,都会导致上下文的不一致,进而导致缓存失效。
二、需要更新信息时,用消息而不是改提示词
提示词里的信息会过时,比如时间变了、用户更新了文件内容。这时候本能反应是直接改提示词——但这会导致缓存命中失败,代价很高。
更好的做法是在下一轮对话里用消息告诉模型。Claude Code 的做法是在用户消息或工具结果里塞一个 <system-reminder> 标签,告诉模型"现在是星期三"之类的更新信息。这样缓存就能保住。
三、别在会话中途换模型
Prompt Cache是按模型隔离的。这是很容易忽略的一点。
比如你已经跟 Opus 聊了 10 万 token,现在想问个简单问题。直觉上可能想切到 Haiku 省钱——但实际上切换后要重建缓存,比直接让 Opus 回答还贵。
如果真要切换模型,正确的做法是用子智能体。Opus 准备一个"交接"消息,把任务交给另一个模型。Claude Code 的 Explore 智能体就是这么干的,它们用 Haiku 做探索任务。
四、永远不要在会话中途增删工具
这是最常见的翻车方式。
直觉上,只给模型当前需要的工具听起来很合理。但工具定义是缓存前缀的一部分,且位置在会话内容之前,在会话中增删工具会让整个对话的缓存失效。
正确做法是对话中始终带上所有工具定义,不中途改动。
五、计划模式:围绕缓存约束来设计功能
计划模式是个很好的例子。
最直观的设计是:用户进入计划模式时,把工具集换成只读工具,避免模型对文件进行更改。但这会破坏缓存。
我们的方案是:工具集不变,把 EnterPlanMode 和 ExitPlanMode 本身做成工具。用户开启计划模式时,模型收到一条系统消息,告诉它现在处于计划模式、该干什么(探索代码库、别改文件、写完计划调 ExitPlanMode)。工具定义从头到尾不动。
这还有个额外好处:模型可以自己判断什么时候该进入计划模式,直接调用工具就行,不会破坏缓存。
六、工具搜索:延迟加载,不要删
Claude Code 可能加载几十个 MCP 工具。全塞进请求里太贵,但中途删除又会破坏缓存。
我们的解决方案是 defer_loading(延迟加载)。
不发完整工具定义,只发轻量级存根——就一个工具名,带上 defer_loading: true。模型需要时,通过 ToolSearch 工具"发现"它,这时候才加载完整的工具模式。
这样缓存前缀会更加稳定:同样的工具名,同样的顺序,始终保持一致。
七、会话压缩:新分支要注意缓存
上下文窗口满了怎么办?压缩——把对话总结一下,开新会话继续。
但压缩和Prompt Cache配合起来,很容易踩坑。
最简单的实现是:单独调一个 API,用不同的系统提示词,不带工具,把整段对话发过去生成摘要。但这样的话,由于系统提示词的更新,Prompt Cache完全无法命中——你要为所有输入 token 付全价,用户成本直接飙升。
正确做法:缓存安全的新分支
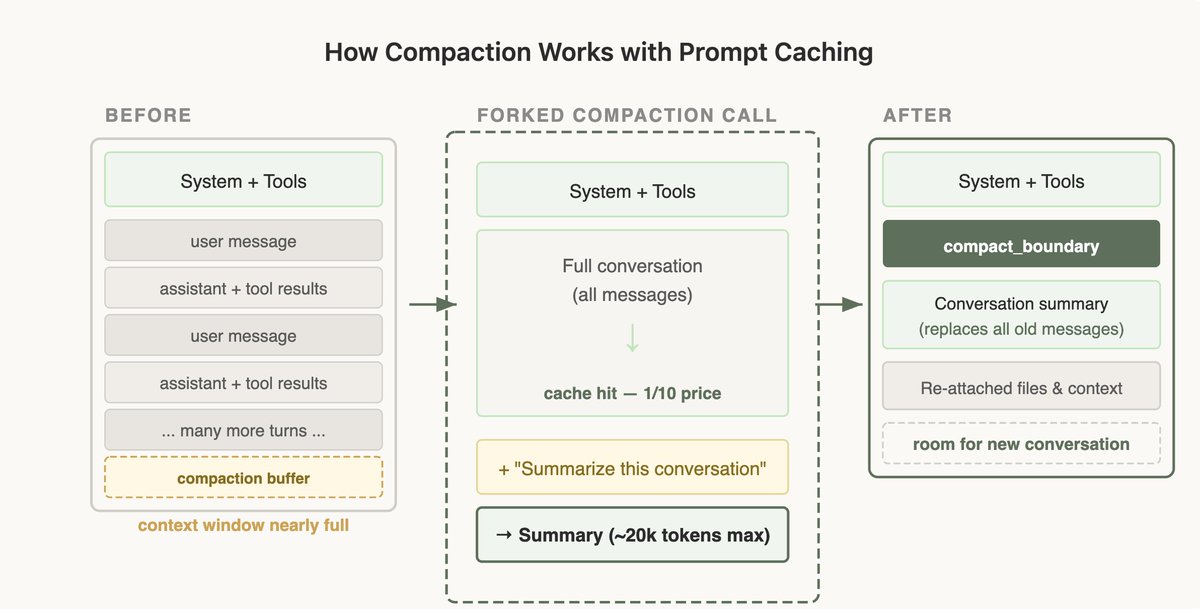
我们压缩时的做法是:用和父对话一模一样的系统提示词、用户上下文、系统上下文、工具定义。前面是父对话的消息,最后追加一条压缩请求消息。
从 API 的角度看,这个请求跟父对话的上一个请求几乎一样——前缀相同、工具相同、历史相同——所以缓存前缀能复用。唯一的新 token 就是那条压缩请求本身。
代价是要留一个"压缩缓冲区",确保上下文窗口有足够空间放下压缩消息和摘要输出。
压缩确实麻烦,但好消息是我们把这些经验直接做进了 API,你不用自己踩一遍坑。
总结一下
Prompt Cache是前缀匹配。 前缀里任何位置的改动,后面全废。设计系统时要把这个约束放在心上。顺序排对,大部分问题自然解决。
用消息而不是改系统提示词。 进计划模式、更新时间这些事,塞消息里比改提示词更安全。
别在对话中途换模型或改工具集。 用工具来模拟状态切换,用延迟加载而不是删除工具。
像监控服务可用性一样监控缓存命中率。 我们把缓存失效当事故处理。几个百分点的命中率下降,成本和延迟就会明显恶化。
分支操作要共享父前缀。 压缩、摘要、技能执行这些辅助计算,要用相同的参数配置,才能吃到父前缀的缓存。
原文链接: